
注:文章内容译自斯坦福大学cs231n课程,只翻译了原文的一部分。
原文请访问:
http://cs231n.github.io/neural-networks-3/#sgd
·······················································································································
最简单的更新方式,沿着负梯度的方向更新参数(梯度指示着函数增长的方向,但我们通常是要最小化损失函数的),假设我们要更新的参数x和其梯度dx,则参数更新的形式如下:
x += -learning_rate * dx
Momentum update
这里的learning rate是个超参数–一个固定的常数。
动量更新是在深度网络中常常收敛更快的一种方法。这种方法收到物理学中动量的启发,可以从物理的角度来看待优化问题。特别地,损失可以解释为丘陵地形的高度(并且因此也可以解释为势能Uαh,因为)。用随机数初始化参数等同于在某个位置设置零初始速度的粒子。然后可以将优化过程视为与在横向上滚动的模拟参数矢量(即,粒子)的过程。
由于粒子上的力与势能的梯度(即)有关,所以粒子受到的力恰好是损失函数的(负)梯度。此外,,所以(负)梯度在该视图中与粒子的加速度成比例。 请注意,这不同于上面显示的更新,其中渐变直接集成了位置。 相反,从物理角度提出了一个更新:梯度只能直接影响速度,而速度又对位置产生影响:
v = mu * v – learning_rate *dx # 整合后的速度
x += v # 整合后的位置
在这里,我们看到一个初始化为零的v变量和一个额外的超参数(μ)的介绍。 作为一个不幸的误称,这个变量在优化中被称为动量(其典型值约为0.9),但其物理意义与摩擦系数更为一致。实际上,该变量减速并降低系统的动能,否则粒子永远不会停在山底。 当交叉验证时,该参数通常设置为[0.5,0.9,0.95,0.99]等值。与学习率的退火计划类似(稍后讨论),优化有时可以从动量计划中获益,其中在后期的学习阶段动量增加。 一个典型的设置是从大约0.5的动量开始,并在多个时期退火到0.99左右。
“With Momentum update, the parameter vector will buildup velocity in any direction that has consistent gradient.(随着动量的更新,参数向量将会建立起在所有方向上都恒定梯度的速度)”
Nesterov动量是与动量更新略微不同的一个版本,最近变得流行起来。它对凸函数的收敛有着很强的理论保证,并且实践中也比标准的动量更新方式效果稍微更好些。
Nesterov动量更新的关键思想是,当目前的参数在某个位置x时,我们知道单独的动量项(即忽略具有梯度的第二项)即将推动参数 矢量由。因此,我们要计算梯度时,我们可以将未来的近似位置视为“前瞻”(lookahead) - 这是我们即将到达的地方附近。因此,计算在处的梯度比“旧”的位置x上的梯度更有意义。
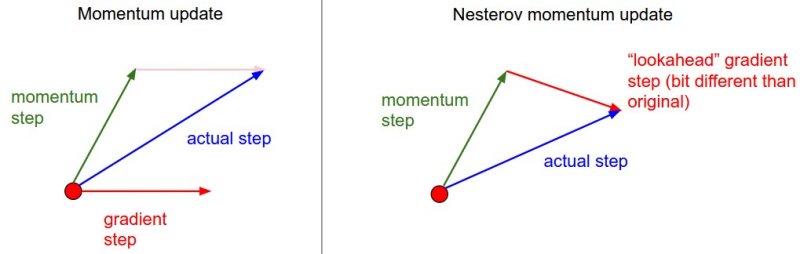
因此,我们将会做如下的计算:
X_head = x + mu * v
v = mu * v – learning_rate *dx_ahead
x += v
Adagrad是一种学习率自适应的方法,最早由 Duchi等人提出。工作方式如下:
假设梯度为dx,参数向量为x, eps为一个很小的数防止分母为0
cache+= dx**2
x +=-learning_rate * dx / (np.sqrt(cache) + eps)
请注意,变量的维度和梯度的维度一样,可以跟踪每个参数的梯度平方和。然后,将其用于对每个维度的参数更新步骤进行归一化。 请注意,大的梯度的权重将降低有效的学习率,而小的或不频繁更新的权重将提高其有效的学习率。 有趣的是,平方根操作是非常重要的,没有它,算法执行得更糟。平滑项(通常设置在1e-4到1e-8的范围内)避免除以零。 的缺点是在深度学习中,单调下降的学习率通常太激进,导致学习太早停止。
是一种非常有效的,但目前尚未发布的自适应学习率方法。 更新以非常简单的方式调整方法,以减少其激进,单调降低的学习率。特别地,它使用平均渐变的移动平均值,给出:
cache = decay_rate * cache +(1 – decay_rate) * dx**2
x += -learning_rate * dx /(np.sqrt(cache) + eps)
这里,是一个超参数,典型取值为[0.9,0.99,0.999]。请注意,‘x + =’的更新与相同,但变量为一种的方式。因此,仍然基于其渐变的幅度调整每个权重的学习率,这具有有益的均衡效果,但与Adagrad不同,更新不会单调变小。
是最近提出的,看起来像的一种基于动量的方法。 (简化版)更新方法如下所示:
m = beta1 * m + (1-beta1)* dx # 动量
v = beta2 * v + (1-beta2) *(dx**2) # cache
x += -learning_rate * m /(np.sqrt(v) + eqs)
请注意,更新完全与相同,不同之处在于使用梯度的“平滑”版本,替代原始(也许有噪声)梯度向量。本文中的推荐值为。 在实践中,Adam目前被推荐为使用默认算法,并且通常比RMSProp略好。 然而,经常也值得尝试SGD + Nesterov动量作为替代。完整的Adam更新还包括一个偏差校正机制,补偿这个现象:最初的几个时间步长中,向量m,v都被初始化,因此在完全“预热”之前都被偏置为零。 利用偏差校正机制,更新如下:(t 是迭代的步数)
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t)
v = beta2*v +(1-beta2)*(dx**2)
vt = v / (1-beta2**t)
x += - learning_rate * mt /(np.sqrt(vt) + eps)
注意到,现在也是迭代步数t的函数了。


可以帮助您建立直觉的学习过程动态的动画。 上图:不同优化算法的损耗曲面和时间演化的轮廓。 注意到基于动量的方法的“overshooting”行为,这使得优化看起来像一座滚下山的球。下图:优化中鞍点的可视化,其中沿着不同维度的曲率具有不同的符号(一维向上和向下弯曲)。 注意,SGD很难打破对称,被困在顶部。 相反,诸如RMSprop的算法在鞍形方向上将看到非常低的梯度。 RMSprop中的分母项将提高沿此方向的有效学习率,从而帮助RMSProp进行优化。图片来源:Alec Radford(https://twitter.com/alecrad)。
Copyright © 2002-2023 众游-众游娱乐化学用品销售站 版权所有 非商用版本 备案号:ICP备9527168号






